日前,中科院自动化所提出了全球首个图文音(视觉-文本-语音)三模态预训练模型“紫东太初”,同时具备跨模态理解与跨模态生成能力,取得了预训练模型突破性进展。
多模态预训练模型被广泛认为是从限定领域的弱人工智能迈向通用人工智能的路径探索,其具有在无监督情况下自动学习不同任务,并快速迁移到不同领域数据的强大能力。
目前,已有的多模态预训练模型通常仅考虑两个模态(如图像和文本,或者视频和文本),忽视了周围环境中普遍存在的语音信息,并且模型极少兼具理解与生成能力,难以在生成任务与理解类任务中同时取得良好表现。针对这些问题,中科院自动化所此次提出的视觉-文本-语音三模态预训练模型分别采用基于词条级别、模态级别以及样本级别的多层次、多任务子监督学习框架,更关注图-文-音三模态数据之间的关联特性以及跨模态转换问题,对更广泛、更多样的下游任务提供模型基础支撑。
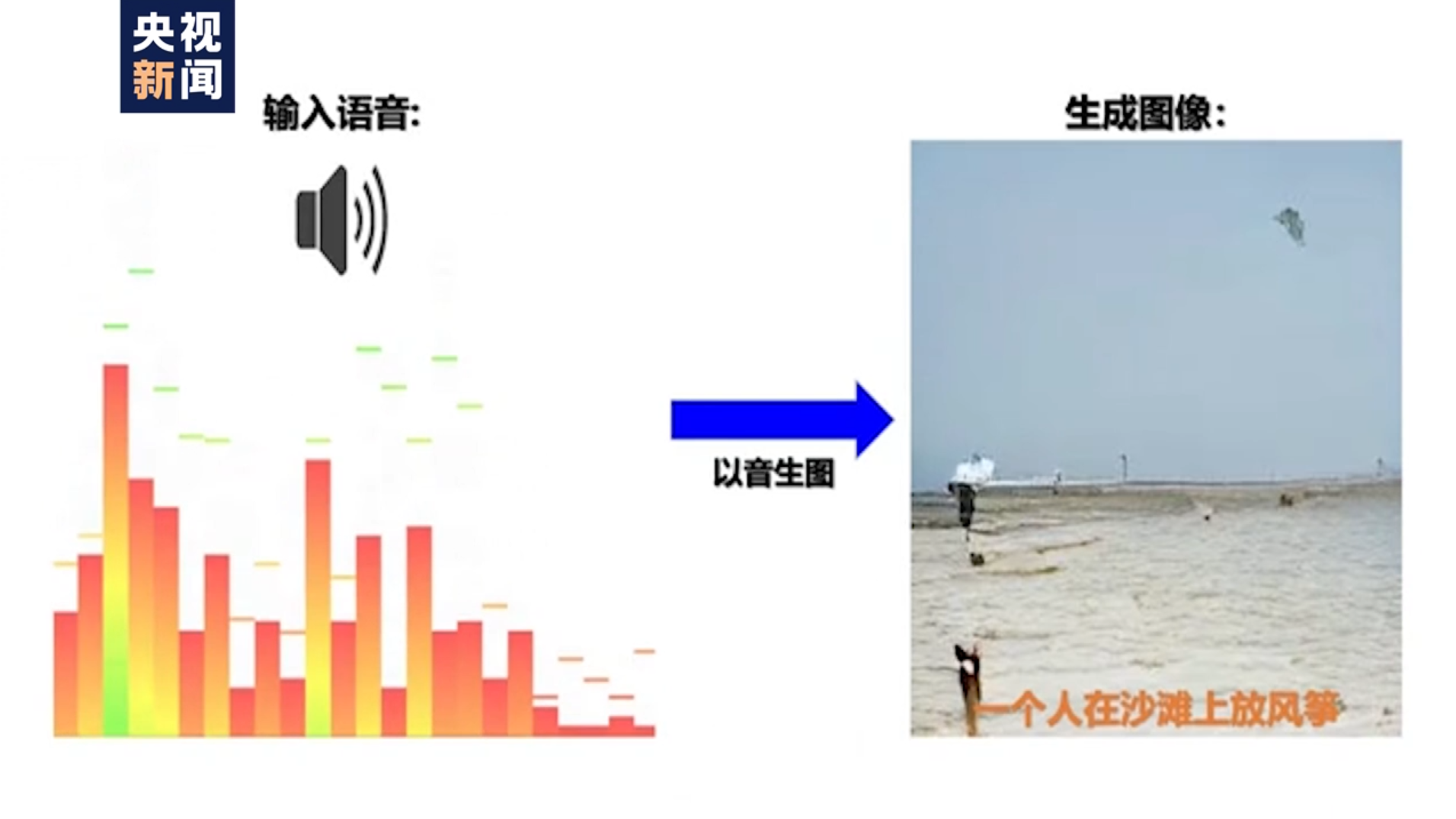
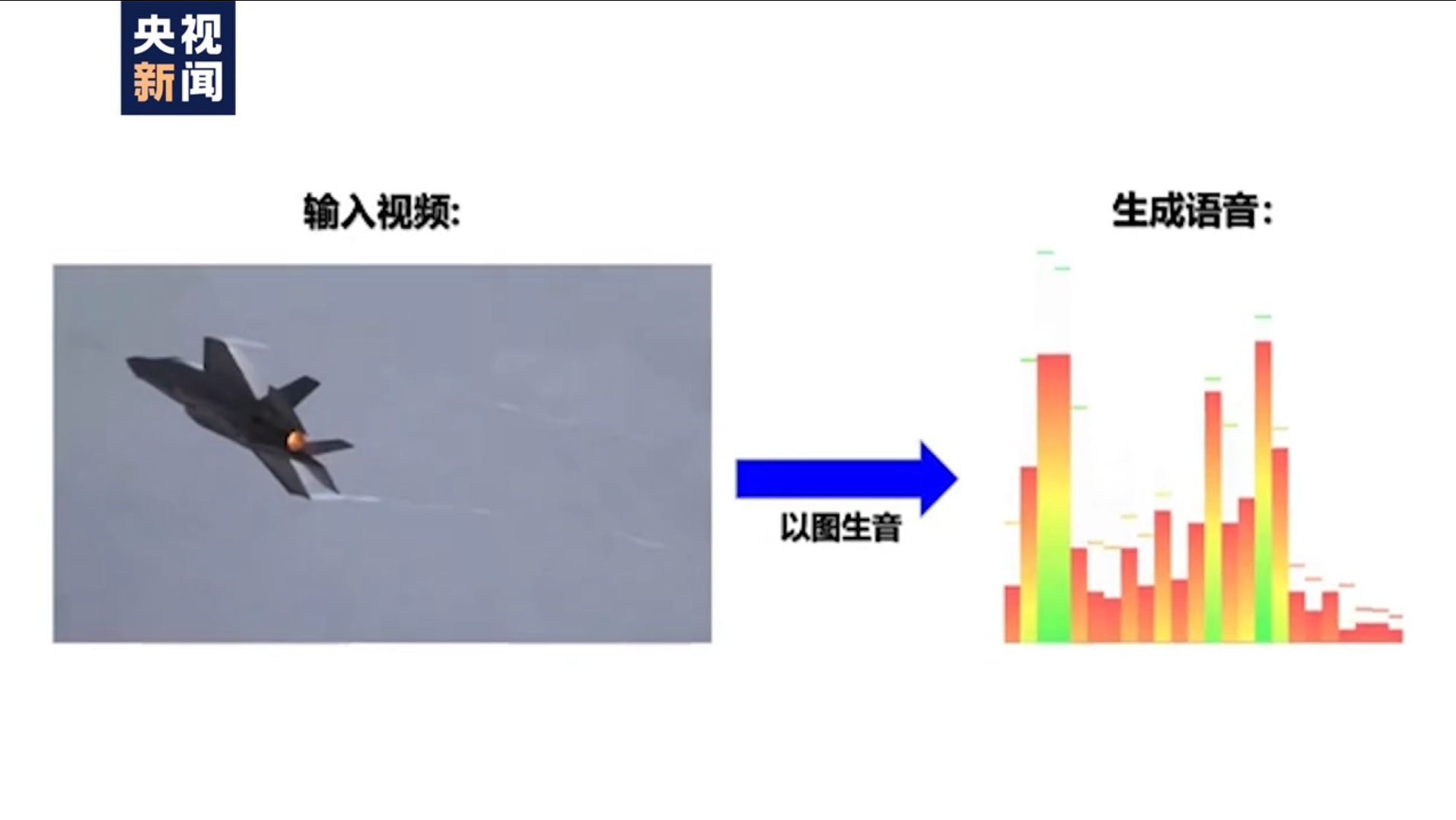
该模型不仅可实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像等任务)。引入语音模态后的多模态预训练模型,可以突破性地直接实现三模态的统一表示,并首次实现了“以图生音”和“以音生图”。此外,科研团队首次提出了视觉-文本-语音三模态预训练模型,实现了三模态间相互转换和生成。
中科院自动化所所长徐波介绍,三模态预训练模型的提出将改变当前单一模型对应单一任务的人工智能研发范式,三模态图文音的统一语义表达将大幅提升文本、语音、图像和视频等领域的基础任务性能,并在多模态内容的理解、搜索、推荐和问答,语音识别和合成,人机交互和无人驾驶等应用中具有重要意义。(总台央视记者 帅俊全)
原文链接:http://m.news.cctv.com/2021/07/09/ARTIWybOOXcK70VE00HO02Pc210709.shtml