在大模型快速发展的今天,越来越多的模型开始具备“深度思考能力”。比如,DeepSeek-R1系列模型通过引入特别的提示词结构:先<think>,再<answer>,使得模型在回答问题之前先进行“深度思考”,生成一整段包含反复自我反思、自我验证的推理过程,然后再给出答案。这一过程显著提升了模型解决复杂问题的能力,但也同时带来了“过度思考”的问题,即模型在解决简单任务时也会生成冗余的推理语句。例如提问 “2+3等于几”,模型却要从自然数定义讲起,列出加法交换律,甚至反复试错,最后才输出答案是5。这种不必要的“过度思考”现象在推理模型中广泛存在。
针对这一问题,中国科学院自动化研究所联合鹏城实验室提出了一种高效的推理策略AutoThink,赋予推理大模型根据题目难度自主切换思考模式的能力:通过所设计的提示词和多阶段强化学习,引导大模型自主决定是否进行深度思考。

具体而言,AutoThink提出了一个简单而有效的方案,它涉及两个核心技术点:
(1)最小提示干预,通过一个添加省略号的Ellipsis Prompt,激活模型随机切换思考模式的能力;
(2)多阶段强化学习,通过三阶段强化学习,模型学会自主根据问题难度切换思考模式。第一阶段让模型稳定地出现快慢两种思考模式,其中“快思考”用于解决简单问题,而对于复杂问题则使用“慢思考”;第二阶段对快慢思考行为进行优化,提高两种模式下正确回答的能力;第三阶段对快慢思考的思维链输出进行精炼。经过这个阶段的训练后,模型不再随机地决定是否深入思考,而是根据问题难度自主选择思考模式。
通过这两者的结合,模型具备了类似人类的快慢思考能力:简单问题直截了当,复杂问题深度推理,真正做到“按需思考”。如图所示,相比之下,传统方法要么手动控制思考模式,要么不区分题目难度,一味地采用简洁推理方法压缩推理过程。
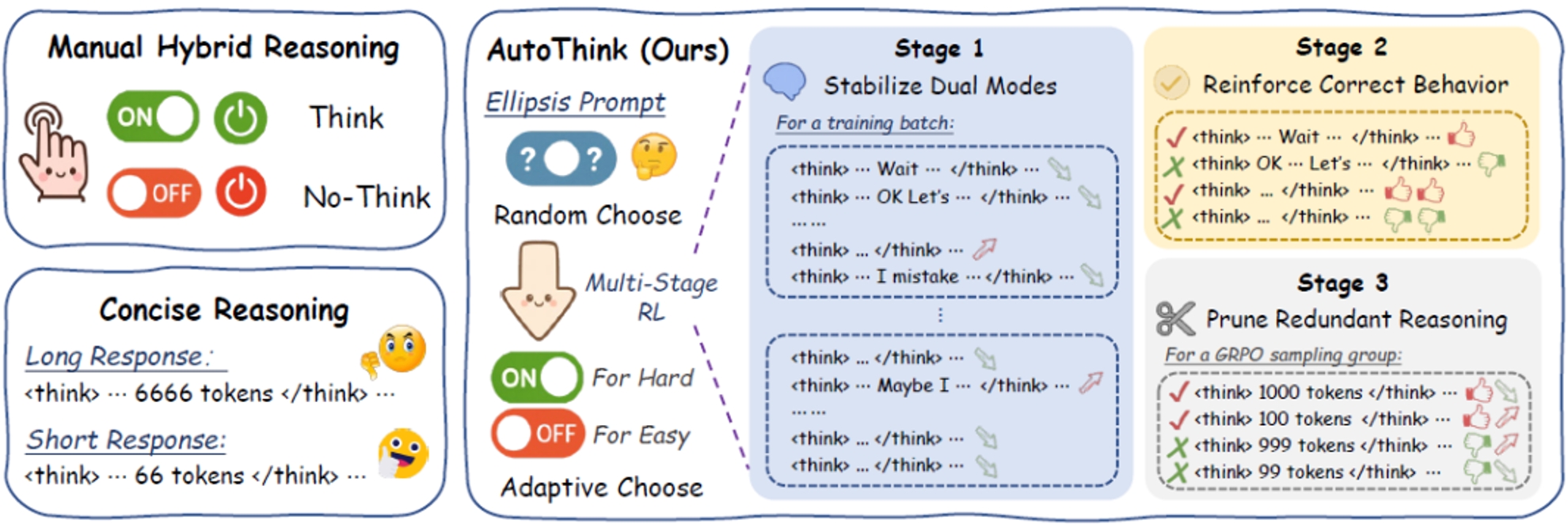
AutoThink与手动控制和简洁推理方法的核心差异:根据难度自主切换思考模式
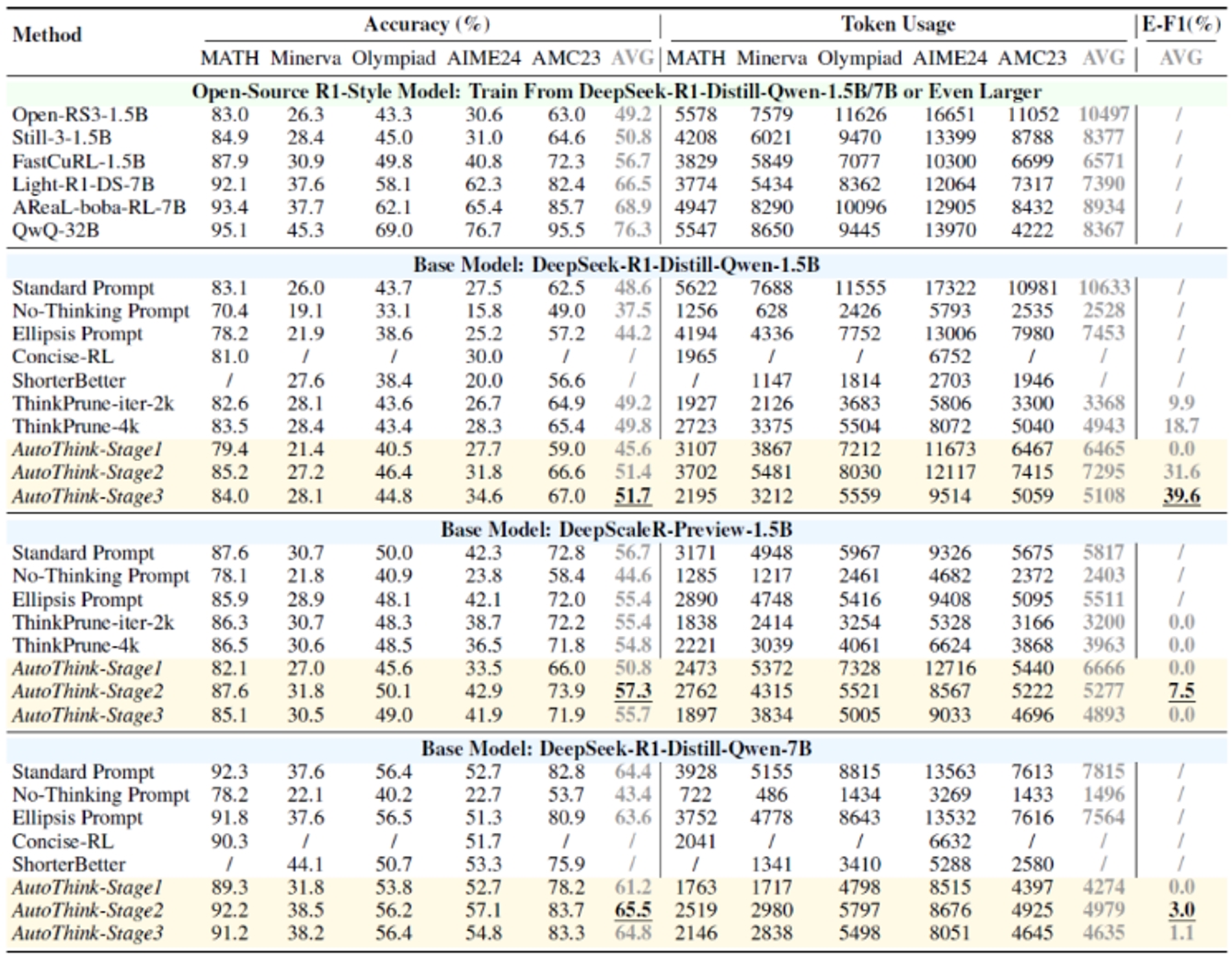
研究团队在多个数学Benchmark和基础模型(R1-Style)上验证了AutoThink。实验结果显示:AutoThink不仅能提升R1蒸馏基模的性能,同时可减少约40%的推理Token消耗,如下表所示。相比之下,大部分开源模型性能增强的代价是推理长度(思考过程)的成倍增长;而简洁思考的模型性能相比于基础模型几乎无提升甚至下降。特别地,即使在已经过大量强化学习后训练的DeepScaleR上,AutoThink依然能额外节省10%的Token消耗。
不同模型和Benchmark上的准确度和推理长度对比
AutoThink提供了一种简单而有效的推理新范式,即通过省略号提示配合三阶段强化学习,引导模型不再“逢题必思”,而是根据问题难度自主决定是否思考、思考多少。在多个数学数据集上,AutoThink实现了优异的准确率–效率平衡,既提升性能,又节省算力,展示出很强的适应性和实用性。
AutoThink已集成于一站式智能科研平台ScienceOne,并将用于训练ScienceOne的基座大模型S1-Base。研发团队表示,让大模型“更聪明地思考、更简洁地表达”,是未来科学基础大模型演进的重要方向。